We often test AI with riddles or coding problems. But the real test of General Intelligence is System 2 Reasoning applied to messy, unstructured visual data.
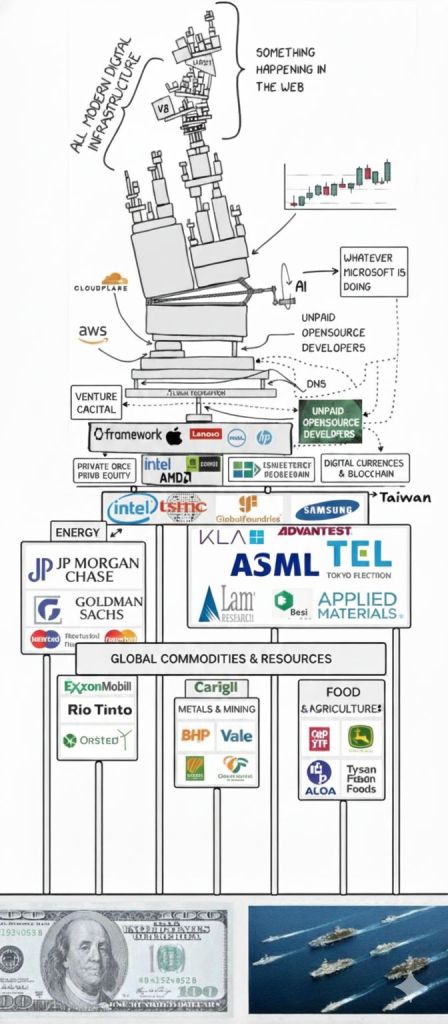
Recently, I ran an experiment with a popular meme (attributed to Dan Magy) depicting the modern digital infrastructure as a precarious “Jenga tower” resting on unpaid open-source developers. I asked Gemini a simple but profound question: What is missing? Add the real-world dependencies.
The result? Gemini didn’t just list companies. It understood the spatial logic of the diagram. It recognized that server farms need electricity (Energy), hardware needs rare earth metals (Commodities), and developers need to eat (Food). Most importantly, it visually “inserted” these layers at the very bottom—the foundation—demonstrating it had crossed the Multimodal Information Gap.
The Challenge: The Multimodal Information Gap
For years, AI suffered from a disconnect between Pixel Space and Concept Space.
OCR (Optical Character Recognition) could read the text “Unpaid Developers.”
LLMs (Large Language Models) knew that “developers need food.”
The Gap: Previous models couldn’t connect the two. They couldn’t look at a drawing of a tower, understand that the Y-axis represents “dependency depth,” and map the semantic concept of “Food” to the spatial location “Bottom (Y=0).”
Gemini bridging this gap means it has a World Model that operates across modalities. It understands that gravity in the image (things fall down) corresponds to dependency in logic (things rely on what is below them).
In the “Jenga” experiment, Gemini didn’t act like a traditional classifier. A classifier sees “Block A” and “Block B.” Gemini, however, acted as a Structural Reasoner. It inferred that if Block A is at the top, and Block A is “Digital Infrastructure,” then there must be a foundational layer supporting it, even if that layer is invisible in the pixel space.
This capability relies on three specific architectural breakthroughs documented in recent arXiv papers: Native Multimodality, Interleaved Reasoning, and Long-Context World Models.
1. The Architecture:
Native Multimodality (No “Connectors”)
Most previous models (like GPT-4V or LLaVA) use a “glue” architecture: they take a frozen vision encoder (like CLIP) and “glue” it to a text model. This results in the Multimodal Information Gap—the model “sees” the image description, but not the raw structural relationships.
How Gemini Solves It:
As detailed in the Gemini 1.5 Technical Report (arXiv:2403.05530) and the recent Gemini 3 System Card, Gemini is natively multimodal. It is trained from the start on interleaved sequences of text, images, and code.
The Mechanism:
The image of the Jenga tower isn’t converted to text. It is tokenized directly into the model’s stream. The model “thinks” in a mixed vocabulary of [text_token, image_patch_token, text_token].
The Result:
It doesn’t just read “Intel”; it sees the pixels of the Intel block physically crushing the block below it. It understands the spatial stress, which maps to the semantic concept of dependency.
2. The Logic: “Needle In A Haystack” & Spatial Grounding
The meme contains a chaotic mix of handwritten text, logos, and arrows. To “patch” it, the model must perform Visual Grounding—mapping abstract concepts (Economics) to specific x,y coordinates (Pixels).
The Research:
In the Gemini 3 Technical Report (Nov 2025), DeepMind introduced “Deep Think” capabilities for visual inputs. This allows the model to pause generation and perform “chain-of-thought” reasoning on the image tokens.
Application:
Scan:Identify the bottom-most bounding boxes
Recall: Access internal world knowledge (e.g., GNoME paper data on materials, AlphaChip data on hardware).
Deduce: “Hardware requires Energy.” “Humans require Food.”
Insert: Generate a new visual/textual layer at y_{new} < y_{bottom}.
3. The Code: Implementing “System Repair”
If we were to implement this “Reasoning Repair” using the Gemini 3 Pro API (simulated based on current capabilities), it would look like this. Note the use of reasoning_config to force the structural analysis:
import google.generativeai as genai
from PIL import Image
# Initialize Gemini 3 Pro with “Deep Think” reasoning enabled
model = genai.GenerativeModel(‘gemini-3-pro-experimental’)
img = Image.open(‘jenga_tower.jpg’)
# The prompt requires cross-modal “System 2” thinking
prompt = “””
You are a Systems Architect. Analyze this visual diagram of global infrastructure.
1. DECODE: Map the visual ‘stack’ to a logical dependency graph (A -> B -> C).
2. DIAGNOSE: Identify the ‘root nodes’ (foundation). Are they physically stable?
3. PATCH: The diagram ends at ‘Intel/Hardware’. This is logically incomplete.
– Insert the missing ‘Physical Reality’ layers (Energy, Mining, Agriculture).
– Return their logical position and the specific companies (Entities) that belong there.
“””
# Enable hidden chain-of-thought to allow “thinking” before answering
response = model.generate_content(
[img, prompt],
generation_config=genai.GenerationConfig(
thinking_mode=”enabled”, # Hypothesis: System 2 activation
temperature=0.2
)
)
print(response.text)
4. Why AGI is “Here-ish“
The term AGI is controversial, but this specific behavior—Structural Generalization—is a key milestone.
Old AI: Could identify “Pizza” in a picture.
Current AI (Gemini 3): Can look at a picture of a pizza, realize the “Dough” layer is missing, and explain why the pizza will fall apart without it.
By connecting the visual fragility of the Jenga tower to the economic fragility of the real world, the model proved it has a unified “World Model.” It doesn’t just process data; it understands the rules that govern it.
Now, you can try building your own reasoning stacks using Vision models and Knowledge Graphs and handle user query using LLM.
More in the next part.


Leave a comment