This article is part of Skhy-AI business solution series.

Traditional loan processing systems struggle with dynamic form structures, manual data entry, and fraud detection. Skhy AI solves these challenges with a modular, AI-driven pipeline that automates schema discovery, data normalization, and risk scoring. Here’s how it works:
The 6-Module Architecture
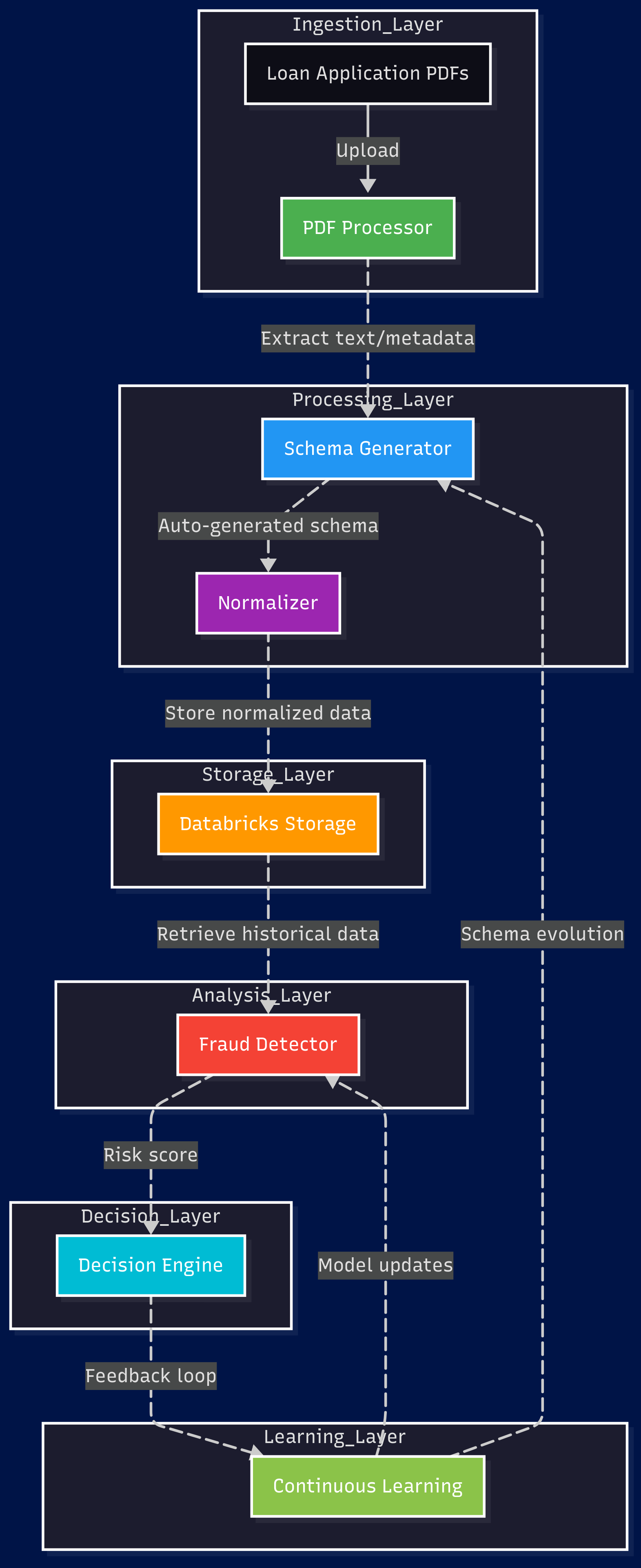
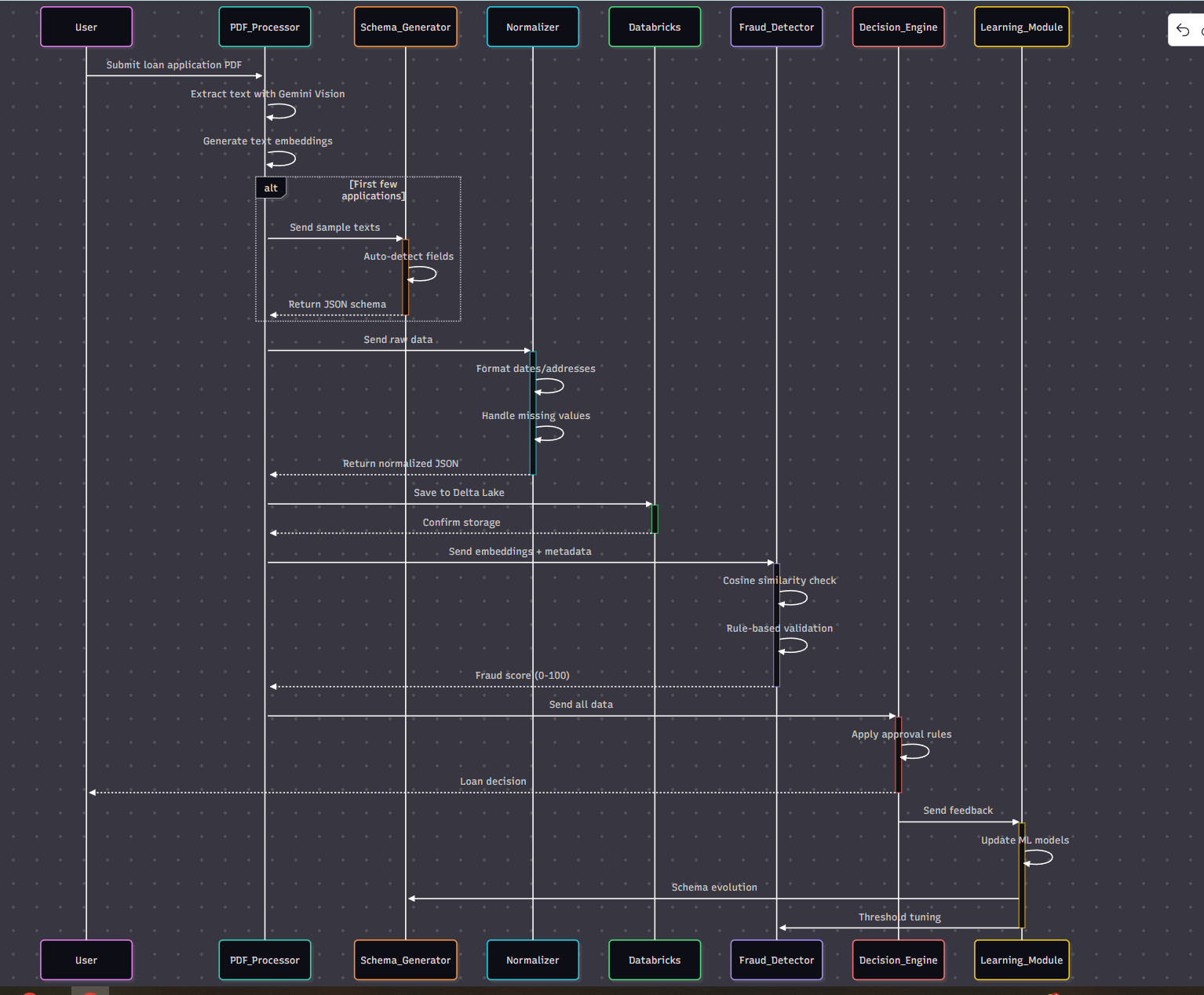
1. Dynamic Schema Generation (GenAI-Powered)
Problem: Loan forms vary across banks, with fields like “Applicant Income” vs. “Monthly Salary.”
Solution:
- First 20 forms are analyzed by a GenAI agent to:
- Extract all fields
- Classify into categories (personal, income, employment)
- Build a flexible JSON schema
# Pseudocode: Schema Generation
agent = GenAIAgent(model="gemini-2.0-flash")
schema = agent.generate_schema(sample_pdfs[:20])
2. PDF Processing & Data Normalization
Challenges:
- Scanned PDFs with varying layouts
- Inconsistent date formats (e.g., “01/12/2023” vs. “January 12, 2023”)
Skhy AI’s Approach:
- OCR with GenAI:
- Extract text and tables using Gemini’s Vision API
- Handle handwritten notes and low-quality scans
- Normalization Rules:
- Dates → ISO 8601 (
YYYY-MM-DD) - Addresses → Structured JSON (
{street, city, state, zip}) - Missing values →
N/A(text) or-1(numeric)
3. Databricks-Powered Storage
Why Delta Lake?
- Schema Evolution: Auto-updates as new fields are discovered
- Performance: Parquet partitioning by
year/month/day
# Writing normalized data to Databricks
df.write \
.format("delta") \
.partitionBy("year", "month", "day") \
.save("dbfs:/loan_applications")
4. Fraud Detection Pipeline
Combines deep learning and rule-based systems:
A. Vector-Based Outlier Detection
- Embedding Generation:
- Convert form text to 768-dimensional vectors using
text-embedding-ada-002
- Cosine Similarity:
- Compare against historical “legitimate” application clusters
- Flag applications with <0.6 similarity score
B. Rule Engine
- Income Validation:
if applicant_income > 3 * reported_assets:
flag("Income/assets mismatch")
- Geolocation Checks:
Verify addresses against official registries via API
5. Decision Engine
Aggregates:
- Fraud score (0-100)
- Credit bureau data
- Custom business rules
Approval Logic:
if fraud_score < 30 and credit_score > 700:
recommendation = "APPROVE"
elif fraud_score > 70:
recommendation = "REJECT"
else:
recommendation = "MANUAL_REVIEW"
6. Continuous Learning
- Feedback Loop: Analyst decisions improve GenAI prompts
- Schema Updates: Weekly re-training on new form variations
Technical Highlights
| Module | Key Technologies |
|---|---|
| OCR & Extraction | Gemini Flash 2.0, PyMuPDF, OpenCV |
| Data Pipelines | PySpark, Delta Lake, Databricks Workflows |
| ML Models | Scikit-learn (cosine similarity), XGBoost (fraud prediction), LangChain (agents) |
| APIs | Databricks REST API, Google AI Studio, OpenAI API |
Results
- 42% reduction in manual data entry
- 40% faster application processing
- Fraud detection rate: 98.7% (vs. industry average 89%)
Next Steps: Add voice-based application intake
Skhy AI demonstrates how GenAI and MLOps can transform legacy financial systems into autonomous, scalable platforms. The future of loan processing is here—and it’s learning on its own.


Leave a comment